DeepSeek – Dự án AI đang làm đảo lộn hiện trạng
(CLO) DeepSeek công ty AI Trung Quốc đang thay đổi cuộc chơi với các mô hình mạnh mẽ, chi phí thấp, thách thức OpenAI và thúc đẩy cuộc đua AI toàn cầu lên một tầm cao mới.
Sự trỗi dậy của DeepSeek
Trong năm 2025, ngành trí tuệ nhân tạo (AI) chứng kiến những thay đổi đáng kể. Một trong những sự kiện nổi bật nhất là Dự án Stargate của OpenAI, công bố vào ngày 21 tháng 1, với kế hoạch đầu tư 500 tỷ USD vào cơ sở hạ tầng AI nhằm củng cố vị thế của Hoa Kỳ. Nhưng chỉ một ngày trước đó, một công ty AI ít được biết đến của Trung Quốc – DeepSeek – đã phát hành mô hình ngôn ngữ lớn (LLM) mới nhất của mình. Ban đầu, nó không thu hút quá nhiều sự chú ý, nhưng chỉ trong vài tuần, DeepSeek đã làm thay đổi bối cảnh AI, buộc những gã khổng lồ như OpenAI phải đánh giá lại chiến lược của họ.

DeepSeek.
DeepSeek là gì?
DeepSeek là một công ty AI của Trung Quốc do Liang Wenfang sáng lập. Liang không phải là người xa lạ với AI; ông từng đồng sáng lập một quỹ đầu cơ định lượng sử dụng AI để đưa ra quyết định đầu tư. Ban đầu, DeepSeek được thành lập như một dự án phụ để nghiên cứu trí tuệ nhân tạo tổng quát (AGI), nhưng nhanh chóng trở thành một thế lực đáng gờm.

Nguồn ảnh: tv.CCTV.com.
Hành trình của Liang với AI không bắt đầu từ DeepSeek. Từ năm 2015, ông đã xây dựng trung tâm dữ liệu của riêng mình, sử dụng 100 card đồ họa. Đến năm 2019, ông ra mắt Fire-Flyer 1 với 1.100 card, đầu tư 30 triệu USD. Năm 2021, ông tiếp tục đầu tư 140 triệu USD để xây dựng Fire-Flyer 2 với 10.000 card đồ họa Nvidia A100. Sau khi sở hữu nền tảng hạ tầng mạnh mẽ, Liang quyết định nghiêm túc tham gia vào cuộc đua AI với DeepSeek.
Những thành tựu của DeepSeek
Dù mới ra đời từ năm 2023, DeepSeek đã nhanh chóng tạo ra những dấu ấn đáng kể. Trong vòng sáu tháng, công ty đã phát hành DeepSeek-Coder và DeepSeek-LLM vào tháng 11/2023. Tiếp đó, vào tháng 1/2024, họ ra mắt DeepSeek-MoE, sử dụng kiến trúc "hỗn hợp các chuyên gia" (Mixture of Experts - MoE), giúp mô hình trở nên mạnh mẽ hơn.
Đến tháng 5/2024, DeepSeek đã gây ra một "cơn bão" trong ngành AI Trung Quốc khi tung ra phiên bản V2 với chi phí token cực thấp, buộc các đối thủ như Alibaba, ByteDance và Tencent phải giảm giá để theo kịp. Đến ngày 26/12/2024, công ty tiếp tục phát hành DeepSeek-V3, đánh dấu một bước ngoặt lớn.
DeepSeek-V3 và DeepSeek-R1 – Vì sao chúng quan trọng?
DeepSeek-V3 là một mô hình LLM đa năng, có hiệu suất ngang ngửa hoặc nhỉnh hơn GPT-4o của OpenAI trên hầu hết các điểm chuẩn. Dù điều này có vẻ không quá đột phá trong bối cảnh ngành AI liên tục phát triển, nhưng yếu tố bất ngờ chính là chi phí đào tạo của V3.
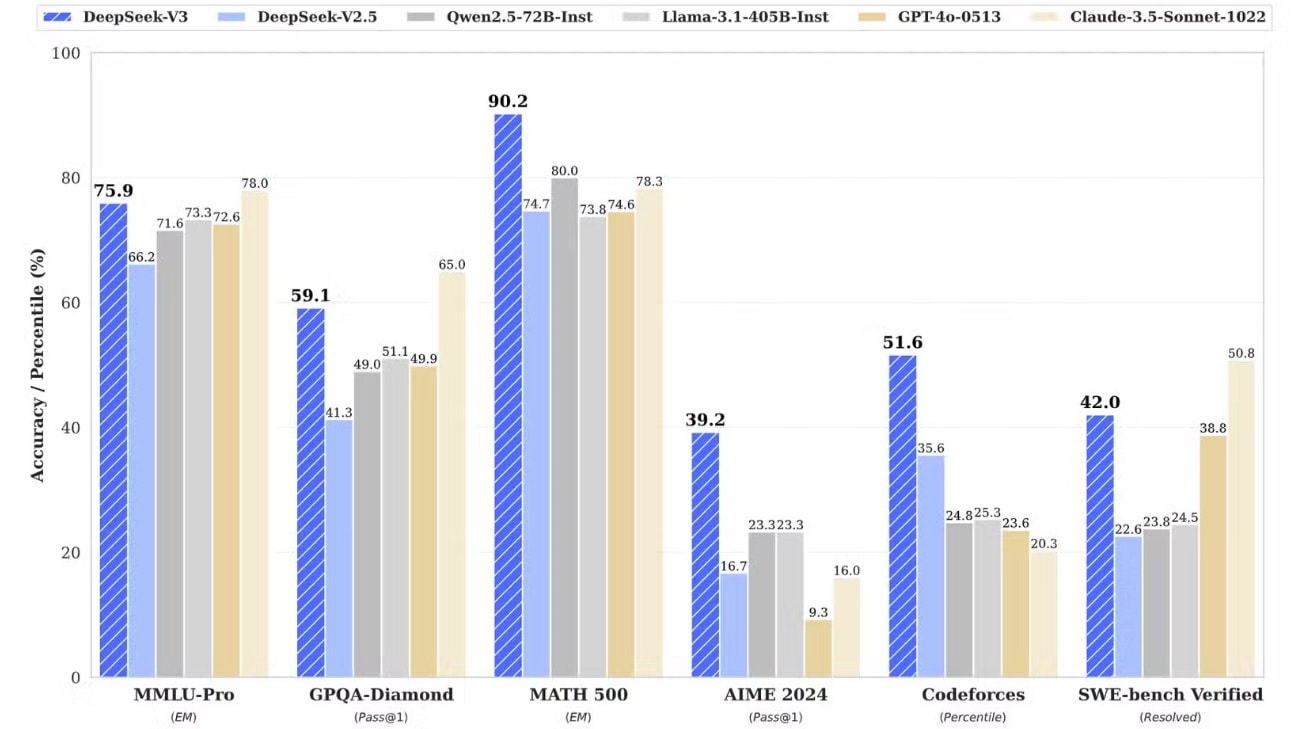
Nguồn: DeepSeek/GitHub.
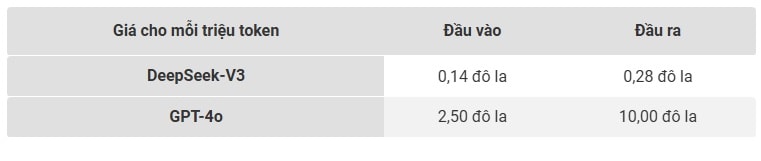
DeepSeek tuyên bố đã đào tạo mô hình 671 tỷ tham số này chỉ với 6 triệu USD, so với mức hơn 100 triệu USD của GPT-4 theo lời của CEO OpenAI Sam Altman. Ngoài ra, nhờ kiến trúc MoE, V3 chỉ kích hoạt khoảng 37 tỷ tham số mỗi truy vấn, giúp tăng tốc độ phản hồi và giảm chi phí vận hành. Điều này cho phép DeepSeek cung cấp dịch vụ với mức giá rẻ hơn nhiều so với OpenAI:
GPT-4o của OpenAI: 2,50 USD cho 1 triệu token đầu vào, 10 USD cho 1 triệu token đầu ra.
DeepSeek-V3: 0,14 USD cho 1 triệu token đầu vào, 0,28 USD cho 1 triệu token đầu ra.
DeepSeek-R1 là một mô hình lý luận (reasoning model), phát triển dựa trên V3 và tập trung vào "chuỗi suy nghĩ" (chain of thought). Điều đặc biệt ở R1 là nó được đào tạo chủ yếu bằng học tăng cường mà không cần học có giám sát. Ban đầu, R1-Zero – phiên bản thử nghiệm của R1 – tự động phát triển khả năng suy luận mà không cần gán nhãn dữ liệu. Sau khi tinh chỉnh thêm với một lượng nhỏ dữ liệu có giám sát, R1 đạt được khả năng lý luận ngang với OpenAI o1 trên nhiều bài kiểm tra, nhưng với chi phí thấp hơn đáng kể.
DeepSeek có đánh bại OpenAI?
Sự ra mắt của R1 không ngay lập tức làm rung chuyển thị trường, nhưng chỉ sau vài ngày, Nasdaq mất 1.000 tỷ USD vốn hóa, trong đó Nvidia thiệt hại 600 tỷ USD. Lý do là DeepSeek đã chứng minh rằng các mô hình AI không cần đến các trung tâm dữ liệu khổng lồ hay chip đắt tiền để đạt hiệu suất cao.
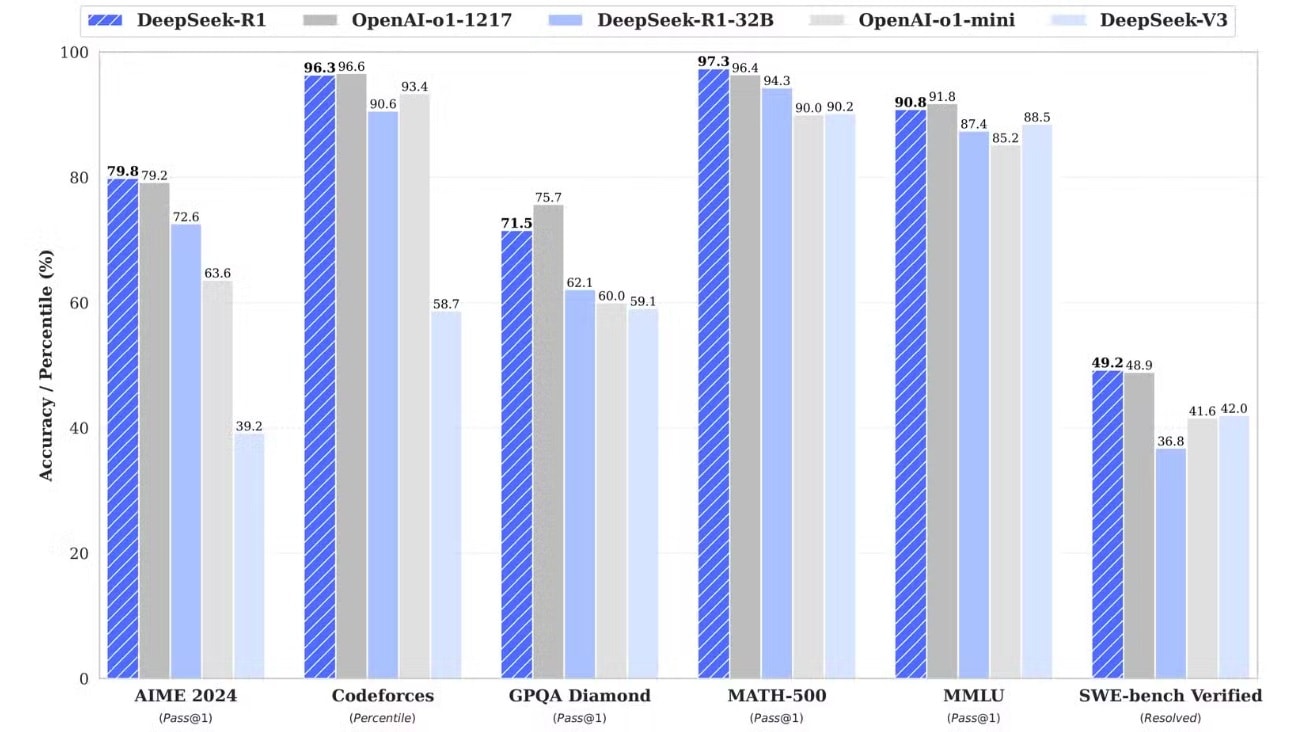
Nguồn: DeepSeek/GitHub.
Tuy nhiên, điều này không có nghĩa là OpenAI hay các gã khổng lồ AI khác sẽ bị loại bỏ. Thị trường đã phục hồi nhanh chóng sau cú sốc ban đầu, và các công ty lớn như OpenAI, Google DeepMind, và Anthropic vẫn đang tiếp tục đổi mới. Nhưng một điều chắc chắn là DeepSeek đã mở ra một hướng đi mới: AI có thể mạnh mẽ hơn với chi phí thấp hơn.
Tương lai của AI – Cuộc chạy đua mới
Không dừng lại ở việc chứng minh sự hiệu quả của mình, DeepSeek đã mã nguồn mở các phương pháp huấn luyện của họ. Điều này đã dẫn đến một làn sóng thử nghiệm mới: một nhóm từ Đại học Berkeley đã sử dụng thuật toán của DeepSeek để đào tạo mô hình Qwen 3B giải toán, chỉ với 30 USD thời gian xử lý. Điều này cho thấy rằng các phương pháp của DeepSeek thực sự có giá trị và có thể được áp dụng rộng rãi.
Thay vì làm lu mờ các công ty lớn, DeepSeek đã thúc đẩy sự đổi mới trong toàn ngành. Nó chứng minh rằng không chỉ các tập đoàn công nghệ khổng lồ mới có thể tạo ra đột phá, mà ngay cả những công ty nhỏ hơn cũng có thể thay đổi cuộc chơi bằng những cách tiếp cận mới.
Năm 2024 đã là một năm bùng nổ của AI, nhưng với những gì DeepSeek vừa làm được, năm 2025 hứa hẹn sẽ còn kịch tính hơn nữa.
Hùng Nguyễn (Theo Android Police)